11月28日消息,在AI大模型的训练与推理领域,NVIDIA显卡的应用率目前遥遥领先,AMD、Intel、谷歌等企业的市场份额难以与之抗衡。那么,NVIDIA究竟凭借哪些优势占据如此领先地位呢?
这里无需强调CUDA生态的优势,也不必罗列AI算子之类的参数,Artificial Analysis直接对当下主流的三大推理方案展开了实际表现对比,具体采用谷歌TPU v6e、AMD MI300X以及NVIDIA H100/B200这几款硬件进行测试比较。
测试涉及的内容不少,但我们只需关注一个综合性指标就行——在30Token/s的速度下,跑Llama 3.3 70B模型时,每百万输入输出对应的成本。
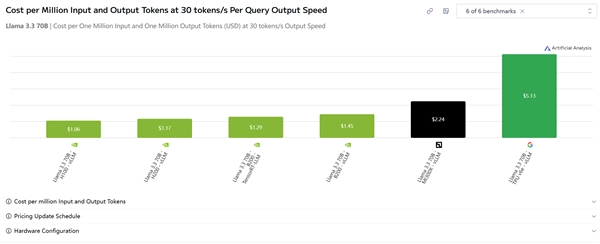
在这方面,H100的成本为1.06美元,H200仅1.17美元,B200 TensorRT是1.23美元,B200为1.45美元,AMD的MI300X达2.24美元,谷歌的TPU v6e则是5.13美元。
对比来看,N卡在性价比方面相比AMD至少有2倍的优势,与谷歌相比则大概有5倍的优势,两者之间的差距十分显著。
即便采用NVIDIA最新且价格最高的B200显卡,成本的增加也不会特别显著,毕竟其性能有了大幅提升,相比AMD以及谷歌的产品依旧保持着较大的优势。
现在可以说,AMD和谷歌目前的AI芯片还有不小差距,但两家的下一代产品提升幅度很大,AMD的MI400X系列最高配备432GB HBM4显存,谷歌的TPU v7据称性能也有几倍提升,到时候或许会改变当前的评测结果。
当然,NVIDIA自然不会坐视不理,其下一代Rubin显卡已正式发布,预计明年将逐步推向市场,有望进一步拉开与竞争对手的差距。





